Case study: How AllianzGI consolidated its middle to back offices
Thierry Saintot, Global Head of Data Management, Allianz Global Investors explains the data benefits from consolidating middle and back office providers.
Thierry Saintot POSTED ON 4/29/2020 6:12:13 PM

 @AllianzGI.
@AllianzGI.
Allianz Global Investors (AllianzGI) is a global asset manager and part of the insurance group Allianz.
We are present in the three regions of the US, Europe, and APAC and in total we have 25 offices. We cover a large spectrum of investment opportunities thanks to our 800 investment professionals.
Back in 2016 AllianzGI was launching a global initiative with respect to middle and back office provider consolidation and I was hired as a global data architect.
My role was to design the data management TOM in this context where AllianzGI would centralise all middle and back office services with State Street.
Getting the basics right
Currently, the financial industry is speaking widely about AI (and more broadly about automation). This is the new hotspot on the IT/ data side.
The interesting thing is that the focus shifted from digital transformation initiatives to AI initiatives.
But still the key success factor for both these kinds of initiatives is to get your ‘source” data in good order (completeness, quality, etc.) so you can derive the desired outputs from it.
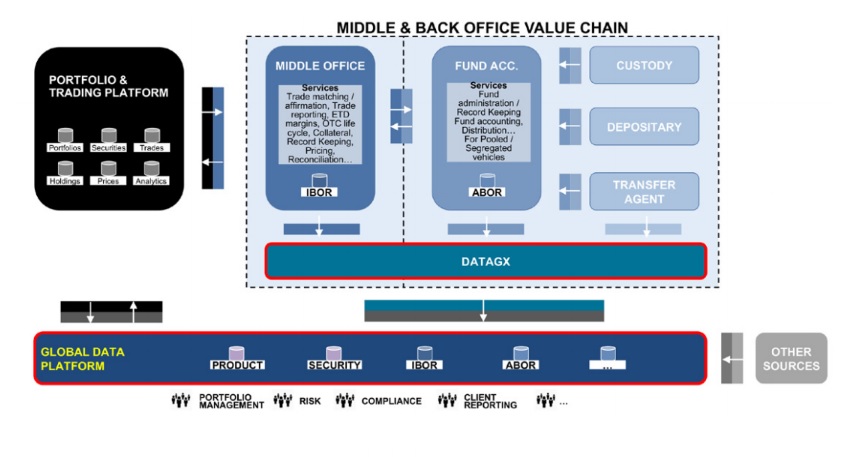
In the asset management business, the “core” data comes from the front-to-back operations value chain. This is where all data related to the invested universe come from.
"The focus shifted from digital transformation initiatives to AI initiatives."
If you don’t make this value chain effective, at least from a data standpoint, this will definitely endanger the rest of your initiatives in the digital and/or AI space.
In many investment firms, this is still a challenge to design the optimal front-to-back model and to make it streamlined, efficient and cost-effective.
This stands for the many operational processes as well as for the data derived from these processes.
At AllianzGI, the choice made to appoint State Street as global provider for middle office and back office services has opened new opportunities to organise and manage our ‘core’ data.
Breaking the functional siloed view
The industry usually sees the front-to-back value chain as vertical (1- Front / 2-Middle / 3-Back) and gives prominence to a functional siloed view.
The key question is: who should I appoint for this particular service in this particular country or region?
The resulting model can be complex to manage, in particular when multiple middle and back office providers are involved, as they usually use a different set of systems and run a different set of processes.
"The key question is: how to make the data the ‘best usable data’ for all components of the value chain?"
At the opposite end, from a data standpoint, the view is that data is a common and transversal asset in the front-to-back value chain i.e. one particular data set produced by one function is re-used and sometimes even enriched by both the others.
The key question is: how to make the data the ‘best usable data’ for all components of the value chain?
Operating with one global middle and back office provider allows you to develop the convergence between the usual vertical / siloed functional view and the transversal data view.
"The important concept is that the three functions ‘front’, ‘middle’, ‘back’ produce and use highly fungible data sets."
A basic example of ‘transversal data’ is a particular trade booked in the front office platform that will materialise in a transaction in the investment book of records (IBOR)* (produced by the middle office function) as well as a transaction in the accounting book of records (ABOR) ** (produced by the back office function).
The important concept is that the three functions ‘front’, ‘middle’, ‘back’ produce and use highly fungible data sets.
While indeed some differences will exist in data sets like IBOR and ABOR (traded view vs settled view, close price vs snap price at a certain point in time, etc.), the vast majority of the data attributes for that particular trade remains unchanged: static attributes of the security traded, trade date, settlement date, nominal or quantity, etc.
The concept of trans-versality of the data across the front-to-back value chain is the genesis of a consolidated ‘front-to-back data platform’.
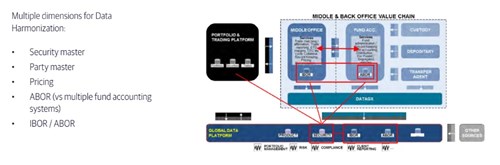
Key factors for a front-to-back data platform
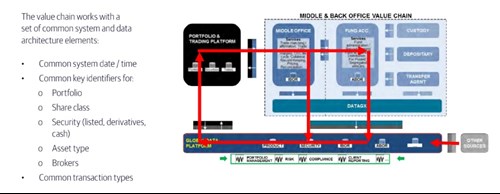
We see 3 key factors for the implementation of a streamlined, efficient and cost-effective front-to-back data platform: system interoperability, standardisation of processes (driving the data) and data harmonisation.
They apply to the specific model that AllianzGI and State Street are running (full outsourcing to one global provider) but also to the many possible permutations of a front-to-back operating model (fully in-house, partially outsourced, or fully outsourced to one or many providers).
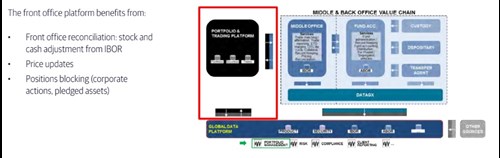
- System interoperability: you focus on the interoperability of your front office platform with the middle and back office platform; this means you work out all data interfaces and define robust matching logics between functions/systems throughout the value chain, including those prevailing between the middle and back office provider(s)
- Standardisation of processes: you focus on the design of globally harmonised processes together with the middle and back office provider(s) (trade matching, exchange-traded derivative (ETD) life cycle, over-the-counter (OTC) life cycle, corporate actions, fund accounting, etc.) - wherever you can operate; this allows you, incidentally, to develop and optimise your own global setup
- Data harmonisation: you focus on the design of globally harmonised data sets that the middle and back office provider(s) will produce on your behalf (like IBOR and ABOR), with the aim of offsetting the ‘differences in the data’ coming from different systems and related accounting processes; you can then design the highways (global interfaces) that will channel the harmonised data sets inside your infrastructure
Examples of benefits coming from the three elements above are: low rate of breaks in the data workflows, uniformity in the way processes (driving data attributes) are performed, consistent meaning of the data attributes across the regions / the accounts / the data sets, standard interfaces for global data deliveries, etc.
All of these contribute overall to streamlined workflows and optimal resource allocation assigned to workflow and interface management.
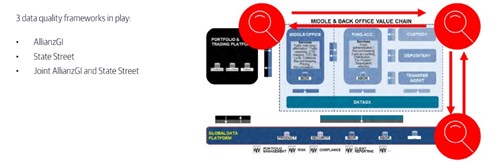
Exploring shared data governance
Last but not least, data quality is another key output that you want to achieve with your front-to-back operating model.
Here again the concept of trans-versality must apply: data quality is a shared and transversal responsibility in the front-to-back value chain.
"In a model with full outsourcing to one global provider, the alignment of all stakeholders towards data quality is less complex to achieve. "
There is no point only focussing on one piece of the puzzle if the rest of the value chain does not work out the data quality problem with the same level of importance. The statement ‘garbage in / garbage out’ applies in full, as every function in the value chain is consuming the data produced by both the others.
In a model with full outsourcing to one global provider, the alignment of all stakeholders towards data quality is less complex to achieve. The fewer parties involved the better.
In the specific model implemented between AllianzGI and State Street, we have invested our focus on the concept of ‘shared data governance’ and ‘shared data stewardship’. We basically see ourselves as jointly responsible for data quality.
In practice, this is about defining the data controls that need to be implemented, the optimal location of the data controls (at which step in the process a particular data control should be performed) and the optimal timing for these data controls (given cut-off times for the processes or the scheduling of job streams) to ensure end-to-end good quality of the data.
"We have invested our focus on the concept of ‘shared data governance’ and ‘shared data stewardship’"
When the principle of ‘shared data governance’ is agreed and effectively implemented, it is possible to have one function running a data control dedicated to preventing data issues impacting another function.
Overall, the complete front-to-back value chain becomes impressively efficient if shared data governance is applied.
This case study is taken from the research report Fund Technology, Data & Operations Europe 2020. To download the full report click here.

Please Sign In or Register to leave a Comment.
SUBSCRIBE
Get the recent popular stories straight into your inbox